前言
之前实现了对首页所有新闻内容的爬取,现在希望实现翻页,爬取更多的新闻。
翻页机制分析
cnbeta的翻页机制是:当滚动到底部时,自动加载下一页的内容,而页面不刷新。这说明翻页是通过ajax实现的。
为了找到请求翻页的url,我们先来抓个包:
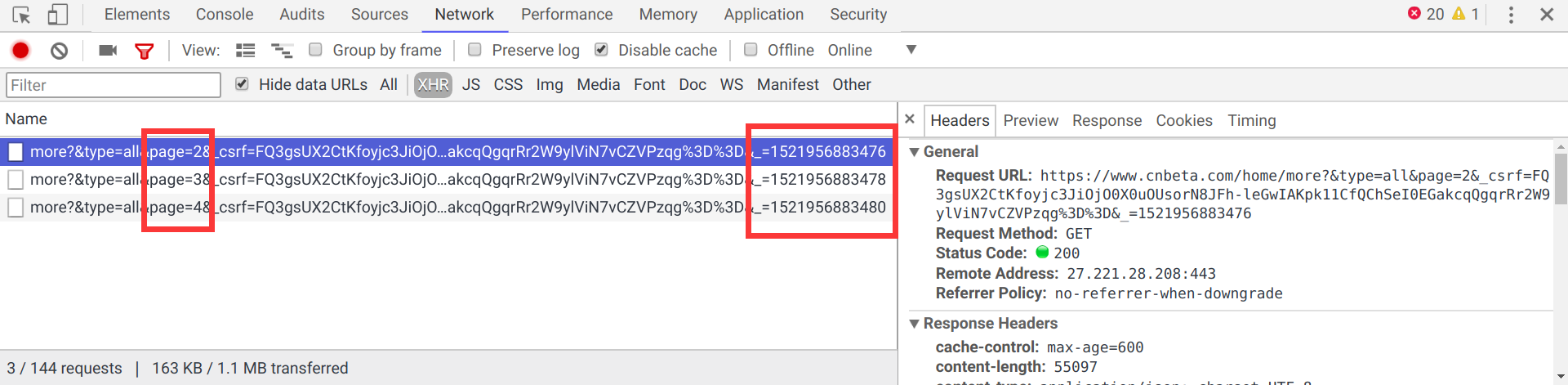
这是一个GET请求,包含4个参数:
type:类型,固定为all即可page:页数,根据需要访问的页数调整_csrf:csrf token,用于防止跨站请求伪造,对于一个session值是固定的_:随着翻页数值上递增2,暂时不明白其含义
一个很自然的想法是,试一下能否用这个规律获取第5页的内容。按照上述规律,第5页的url应该是:https://www.cnbeta.com/home/more?&type=all&page=5&_csrf=FQ3gsUX2CtKfoyjc3JiOjO0X0uOUsorN8JFh-leGwIAKpk11CfQChSeI0EGakcqQgqrRr2W9ylViN7vCZVPzqg%3D%3D&_=1521956883482
结果发现返回值是:
1 | { |
啥都没有。
另外还发现一个现象:前几页的url直接放在地址栏中访问是有返回数据的,但是过了一段时间再访问就没有数据了。这说明这个_很可能与当前时间也有关系。
总之,现在无法掌握这个_的规律,除非把js通读一遍,或者模拟浏览器环境。现在看来这条路是走不通了。
另辟蹊径
经过高人指点,我发现cnbeta还有移动版,URL是https://m.cnbeta.com/。
经过简单翻看,发现最新新闻的url是https://m.cnbeta.com/list/latest_1.htm,那么很显然,第n页的url就是https://m.cnbeta.com/list/latest_n.htm
根据这个规律,可以这样修改主体循环:
1 | export default async () => { |
找到了翻页的方法,接下来就是把页面解析部分改成能解析移动版的网页就行了。
改造parser
这里还有一个问题:现在新闻列表中没有时间信息了,也就是说如果需要时间,那么需要在新闻内容页获取。
我的解决方案是:将getContent的返回类型改为string[],同时传递正文内容和时间:
1 | const getContent = async (url: string) => { |
而parse函数也做相应的修改:
1 | const parse = async (response: superagent.Response) => { |
运行以后发现一切正常。
现在数据库中的数据量太多了,如果在RSS页面渲染的时候全都取出来,那么性能会受到很大的影响。
因此我对查询做出了一个改动,限制每次从数据库中拿20条记录(如果一个用户刚刚订阅这个RSS源,也没有必要显示很久以前的新闻对吧):
1 | const news = await News.find({}).sort({time: -1}).limit(20).exec(); |
RSS的时间格式
仔细阅读Date的文档后,发现Date其实自带一个转换为RSS时间格式的函数toGMTString()。所以我们可以直接把模板改一下:
1 | doctype xml |
用iPad上的Reeder测试,发现时间显示正常(之前是向RSS源同步的时间,而不是新闻的时间)。
总结
目前的爬取速率控制的机制是:将parse、getContent等函数都改成同步的形式。这样可以保证整个执行流都会等待remoteGet的0.5s睡眠。
但是这样存在2个问题:
- 解析和请求只能串行执行,而我们希望是请求之间串行执行,但是解析、数据库访问可以与请求并行
- 如果有链接失效,只能跳过防止阻塞下一个链接的访问,因此无法重试
在速率控制方面还是要参考大佬们的解决方案,找到最佳实践。
现在针对cnbeta的爬虫已经完成了,接下来就要考虑爬一些其他的网站(比如:知乎日报)了。