前言
数据抓取完成后,一种不错的展示方式是生成一个RSS源(虽然RSS已经凉了)。
现在大概要干这么几件事:
- 使用express框架跑一个服务器
- 按照RSS的格式输出XML,这最好使用模版实现
- 之前爬的是文章简介,现在要爬全文
- 爬得多了需要控制速度
Express
安装
express是目前最流行的nodejs服务器框架。首先安装它:
1 | npm install express --save |
HelloWorld
1 | import * as express from "express"; |
express的书写范式和SpingMVC还是挺相似的,使用get、post等方法匹配协议,使用第一个参数url匹配链接,然后传入一个handler,从request中读取请求数据,将结果写入response中。
更复杂的操作(中间件等)在这里就不多述了。
现在,理论上我们可以按照格式把XML写到response中实现RSS。不过,还是用模板比较好。
Pug
安装
pug是一种基于Nodejs的模版引擎(原来叫Jade,我之前只听说过Jade)。首先是安装:
1 | npm install pug --save |
语法
pug的语法是基于缩进的。每一行的第一个单词表示标签名,之后的是标签的数据(不是元数据)。如果下一行的缩进比这一行更多,那么下一行的标签就是这一行的儿子。
pug也可以在中间引入变量,也有逻辑控制和遍历。这些在模板渲染时根据传入的数据填写这些变量。
最终的模板是这样的:
1 | doctype xml |
每一个item就是一条新闻。因为新闻有很多条,所以使用each ... in ...遍历所有的news(这里的news是所有新闻的数组)。
与express的集成
首先需要在express中设置渲染引擎和模板的位置:
1 | app.set("view engine", "pug"); |
然后在handler中使用render方法渲染,并传入参数news(模板在/Views目录下,文件名为rss.pug):
1 | app.get("/rss", async (req: Request, res: Response) => { |
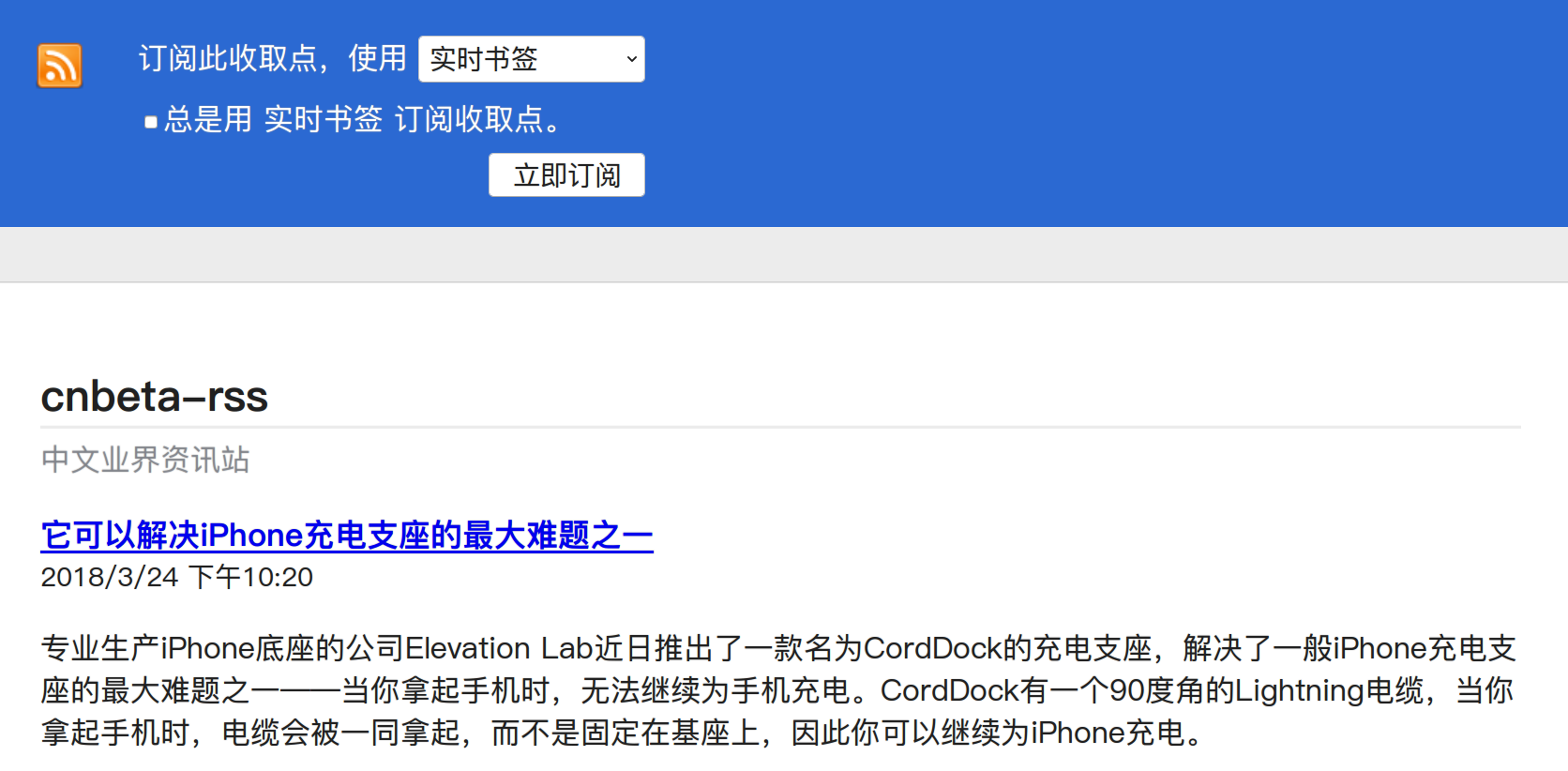
使用Firefox访问http://localhost:8080/rss就可以看到渲染结果了:
express可以把渲染好的页面存起来,避免重复渲染相同的页面。要启用这个功能,需要加一行设置:
1 | app.enable("view cache"); |
npm script
现在还有一个问题:模板作为源文件应该放在/src目录下,但是编译为js后却是在/out目录下寻找。所以在build的时候需要把模板复制到/out目录下。另外我们也希望在build完成后直接运行main.js。
要达到这两个目的,可以修改package.json,使用npm script实现:
1 | "scripts": { |
其中build和postbuild是新加的。build完成了对tsc的调用和对模板的复制;postbuild会在build之后自动执行,其目的是运行main.js。之后在终端中输入npm run build即可执行这两个脚本。
全文爬取
之前的新闻的content是直接从首页中获取的,只有内容的概述。现在我们希望获得新闻的全文。
由于之前我们已经获得了新闻的链接,因此我们可以直接访问新闻的页面,提取出正文的内容:
1 | const getContent = async (url: string) => { |
提取的方式是找到所有的<p>标签,取出标签中的内容,再加上<p>标签后拼接在一起。
parse函数中获取content的语句也要做相应的修改。
爬取速度控制:forEach中的await
cnbeta每页有25条新闻,如果同时发起25次getContent容易被服务器封禁ip,因此需要对访问速度进行限制。
首先想到的方法是,在remoteGet方法中加一句await sleep(1000),这样就可以保证每秒发起一次请求。
不过测试的结果和预期并不一样:实际情况是过了1s后同时发起25个请求,而不是每隔1s发起一个请求。
翻了文档以后发现,Cheerio的each并不会等到callback函数执行完毕才运行下一个(也就是说并不会await callback),这样实际上是生成了25个等待的线程,和预期产生了不同的结果。
现在js的for (... on ...)语句是可以等到循环体执行完毕后再运行下一个的(也就是会await循环体)。所以现在的思路是使用for (... on ...)遍历所有的element:
1 | const items: CheerioElement[] = $(".item").get(); |
$(".item").get()返回所有的CheerioElement的集合。
这里我遇到了一个typescript的坑:编译时报了一个错误:
1 | src/spider.ts(11,11): error TS2322: Type 'string[]' is not assignable to type 'CheerioElement[]'. |
意思是,编译器认为$(".item").get()的返回值类型是string[],与预期类型不服。但是翻看Cheerio的类型声明,可以看到:
1 | get(): string[]; |
也就是说这个函数有三种重载类型,编译器取的是第一种,而我需要的是第二种。
理论上,在我钦定了返回值的类型后,编译器是有足够的信息判断适用哪一种,但是typescript的做法是取匹配到的第一个。这一点在官方文档中也提到了:
Don’t put more general overloads before more specific overloads:
1 | /* WRONG */ |
Do sort overloads by putting the more general signatures after more specific signatures:
1 | /* OK */ |
解决方案有两个:
- 修改类型声明,将我需要的移到第一个
- 修改代码,适用第一个函数
如果需要将代码共享给他人使用,那么只能使用方案二,因为你无法要求他人改库的类型声明。
不过这只是我的个人玩具,为了方便还是选择了方案一。
总结
目前比较好地实现了对新闻的爬取和解析工作,不过还没有很好地支持RSS标准中反人类的时间格式规范。
接下来还是要尝试爬一些不同的网站,比如说做个知乎日报的RSS。